一、编译器概述
1、名词解释
1.1解释下列名词
源语言:被翻译器翻译的语言,用于书写源程序的语言。
目标语言:被翻译器翻译之后得到的语言,用于书写目标程序的语言
翻译器:能够完成从一种语言到另一种语言的变换的软件
编译器:一种特殊的翻译器,要求目标语言比源语言低级
解释器:解释器是不同于编译器的另一种语言处理器。解释器不像编译器那样通过翻译来生成目标程序,而是直接执行源程序所指定的运算。
2、编译阶段
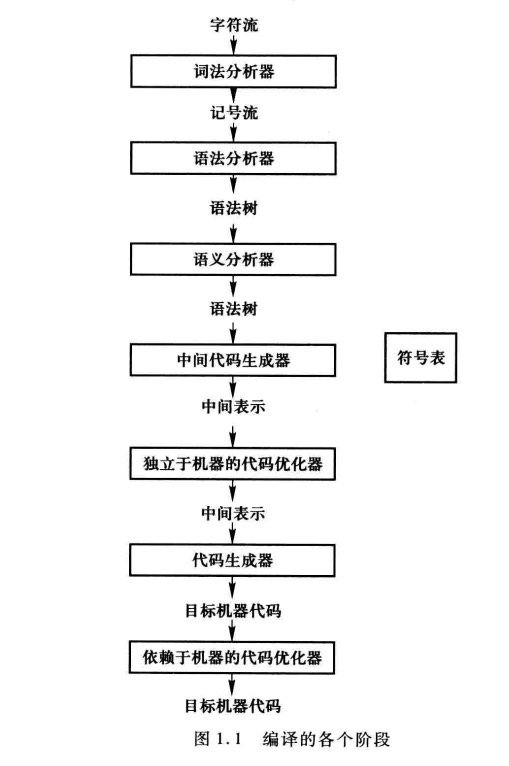
1.2典型的编译器可以划分成几个主要的逻辑阶段?各阶段的主要功能是什么?
典型的编译器可以划分成七个主要的逻辑阶段,分别是词法分析器、语法分析器、语义分析器、中间代码生成器、独立于机器的代码优化器、代码生成器、依赖于机器的代码优化器。各阶段的主要功能:
(1)词法分析器:词法分析阅读构成源程序的字符流,按编程语言的词法规则把它们组成词法记号流。
(2)语法分析器:按编程语言的语法规则检查词法分析输出的记号流是否符合这些规则,并依据这些规则所体现出的该语言的各种语言构造的层次性,用各记号的第一元建成一种树形的中间表示,这个中间表示用抽象语法的方式描绘了该记号流的语法情况。
(3)语义分析器:使用语法树和符号表中的信息,依据语言定义来检查源程序的语义一致性,以保证程序各部分能有意义地结合在一起。它还收集类型信息,把它们保存在符号表或语法树中。
(4)中间代码生成器:为源程序产生更低级的显示中间表示,可以认为这种中间表示是一种抽象机的程序。
(5)独立于机器的代码优化器:试图改进中间代码,以便产生较好的目标代码。通常,较好是指执行较快,但也可能是其他目标,如目标代码较短或目标代码执行时能耗较低。
(6)代码生成器:取源程序的一种中间表示作为输入并把它映射到一种目标语言。如果目标语言是机器代码,则需要为源程序所用的变量选择寄存器或内存单元,然后把中间指令序列翻译为完成同样任务的机器指令序列。
(7)依赖于机器的代码优化器:试图改进目标机器代码,以便产生较好的目标机器代码。
3、有限自动机
有限怎么理解?
DFA和NAF区别?
二、词法分析
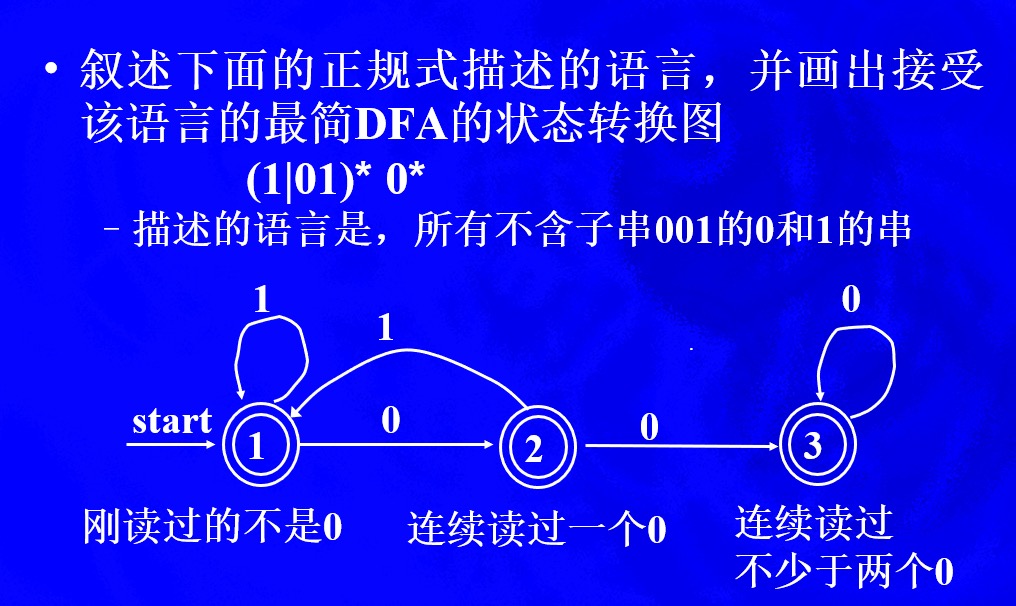
1、正规式

例1
例2
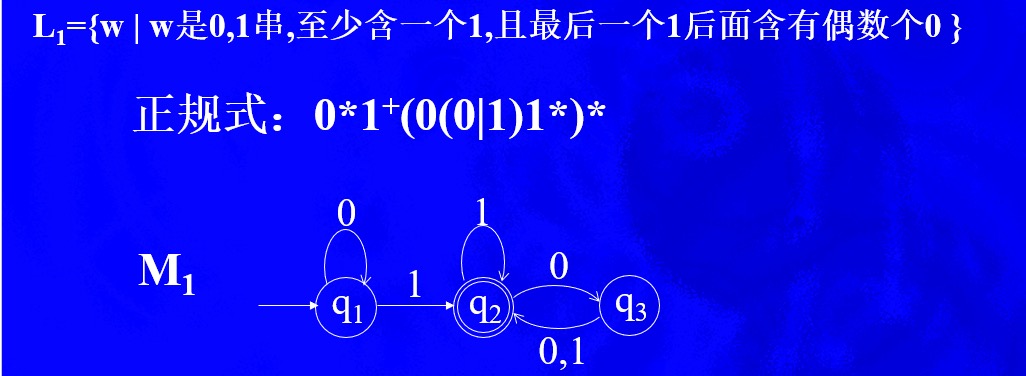
至少含有一个1,因而需要正闭包1+,在出现1后面就会对其后是1还是0选择状态,如果是1,则停留在q2状态上,如果是0进入q3状态。在q3状态上,如果选择0进入q2状态,则实现了1后面两个0,如果是选择1进行q2状态,后面没有0,同样也是符合1后面偶数个0的,这样q2与q3本质是一种等价状态
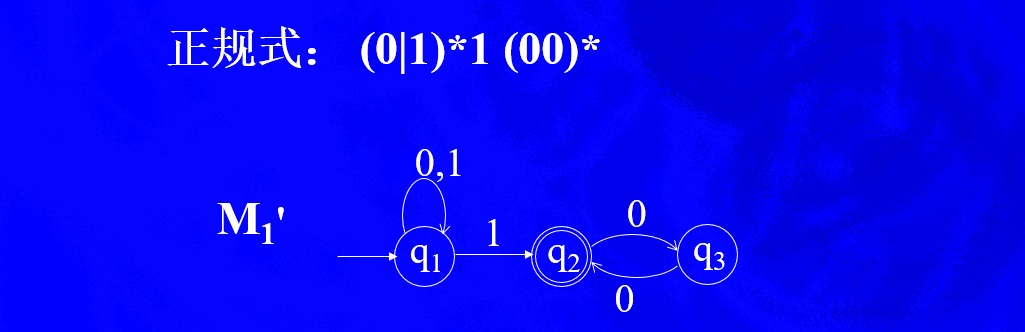
例3
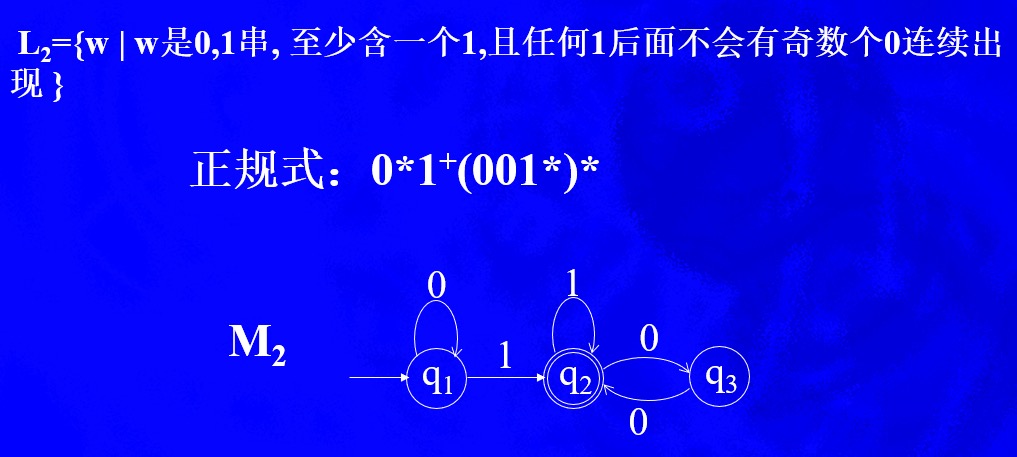
换个意思理解,就是任何一个1后面都有偶数个0
例4

解释:对于L来说描述的语言意思是0的个数是偶数并且1的个数是偶数,原因在于11、00必然是0偶1偶,而01、10要至少出现两次无论是0101,1010,0110,1001都能保证0偶1偶
对于L1
对于L2
对于L3
L2的另外一种表达形式
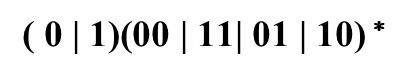
习题2.3
叙述下列正规式描述的语言
a) 0(0|1)0
b) ((ε|0)1)*
c) (0|1)0(0|1)(0|1)
d) 0101010*
e) (00|11)((01|10)(00|11)(01|10)(00|11))
答案:
a)以0开始和结尾,而且长度大于等于2的0、1串
b)所有0,1串(含空串)
c)倒数第三位是0的0、1串
d) 仅含3个1的0、1串
e) 偶数个0和偶数个1的0、1串(含空串)
2、有限自动机
NFA:不确定的有限自动机
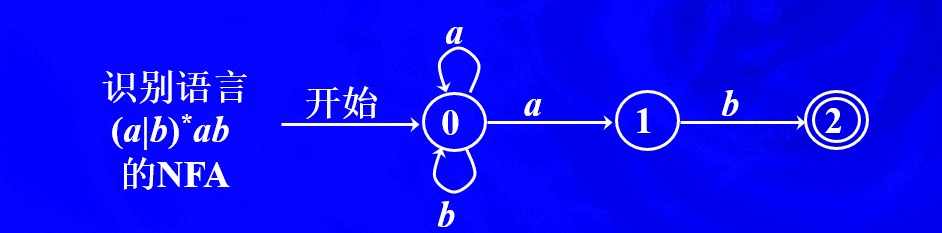
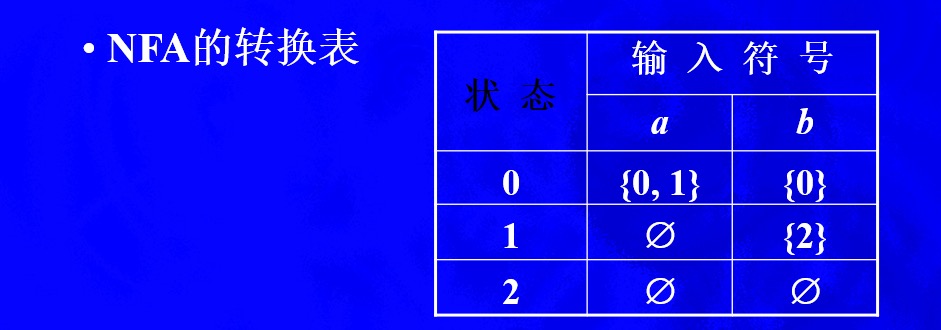
DFA:确定的有限自动机
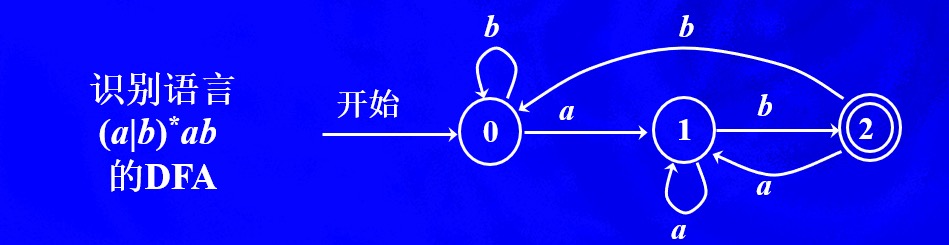
例1
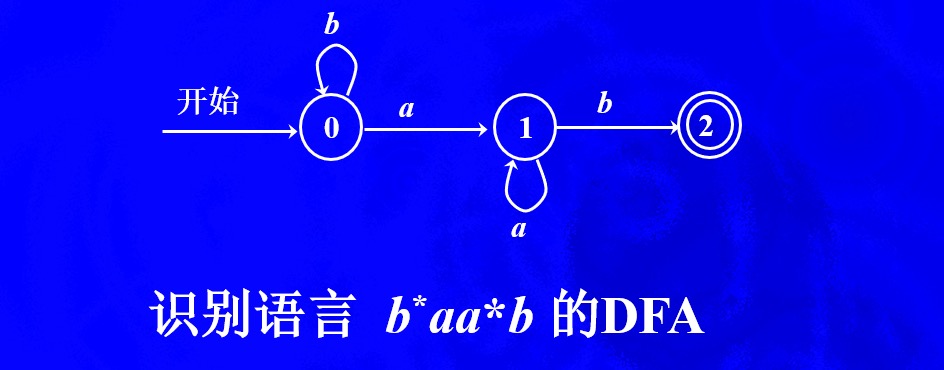
例2
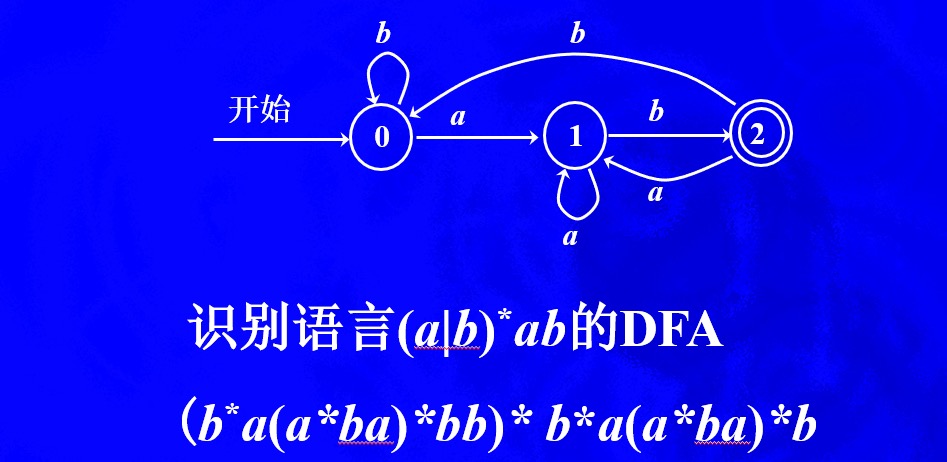
还能表示的正规式是*(b\a+b)+**
例题3
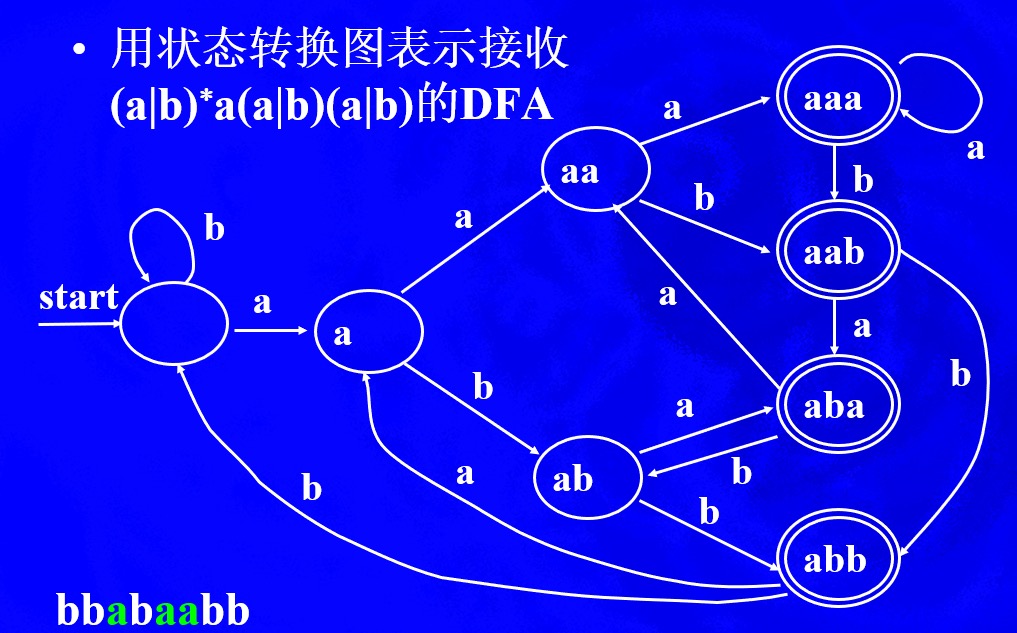
例题4
习题2.7
用算法2.4为下列正规式构造非确定的有限自动机,给出它们处理输入串ababbab的转换序列。
a) (a|b)*
b) (a*|b*)*
c)((ε|a)b)
d)(a|b)abb(a|b)
答案:
a) (a|b)*
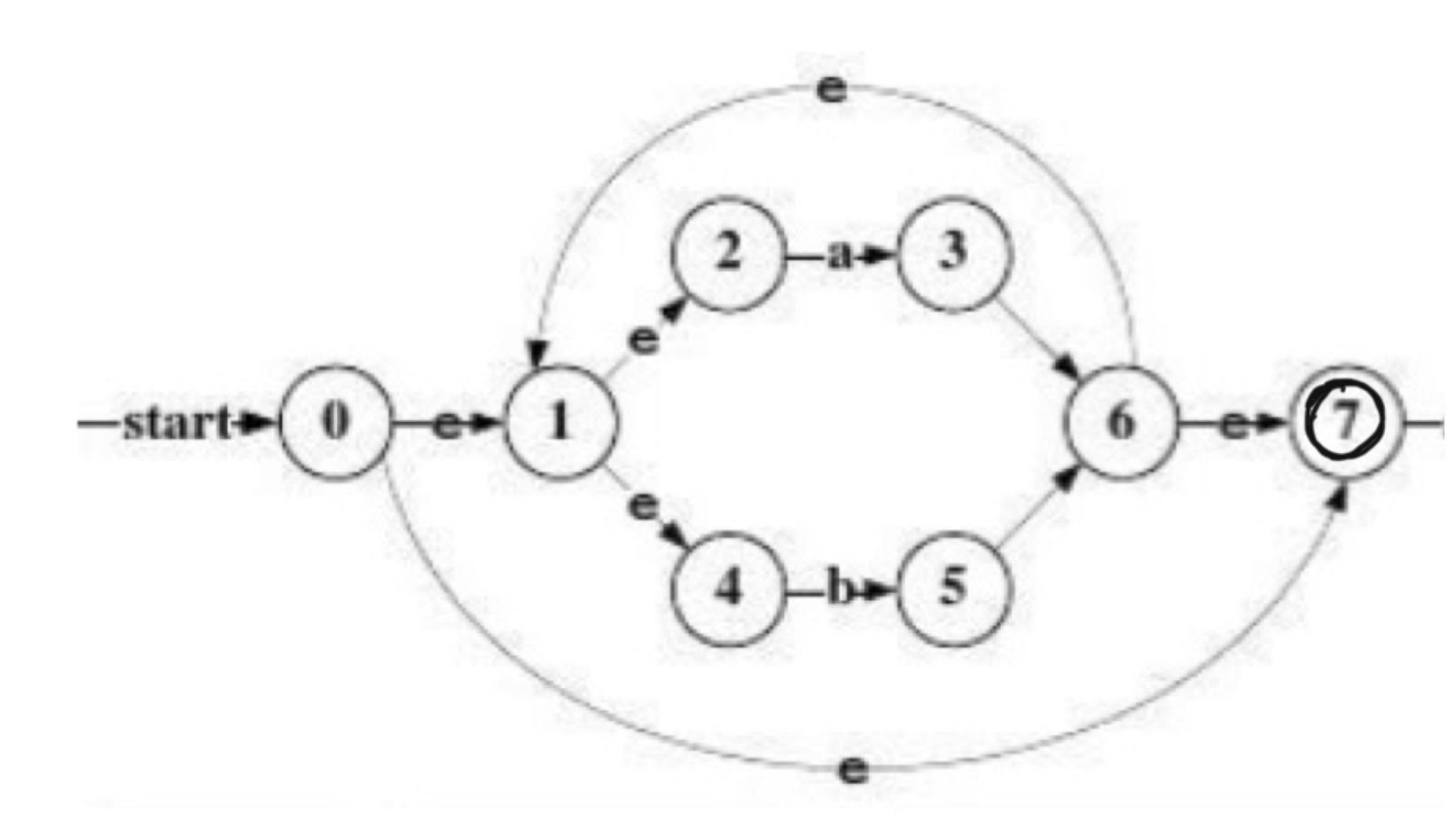
输入串ababbab 的转换序列:
0 1236 1456 1236 1456 1456 1236 14567
b) (a*|b*)*
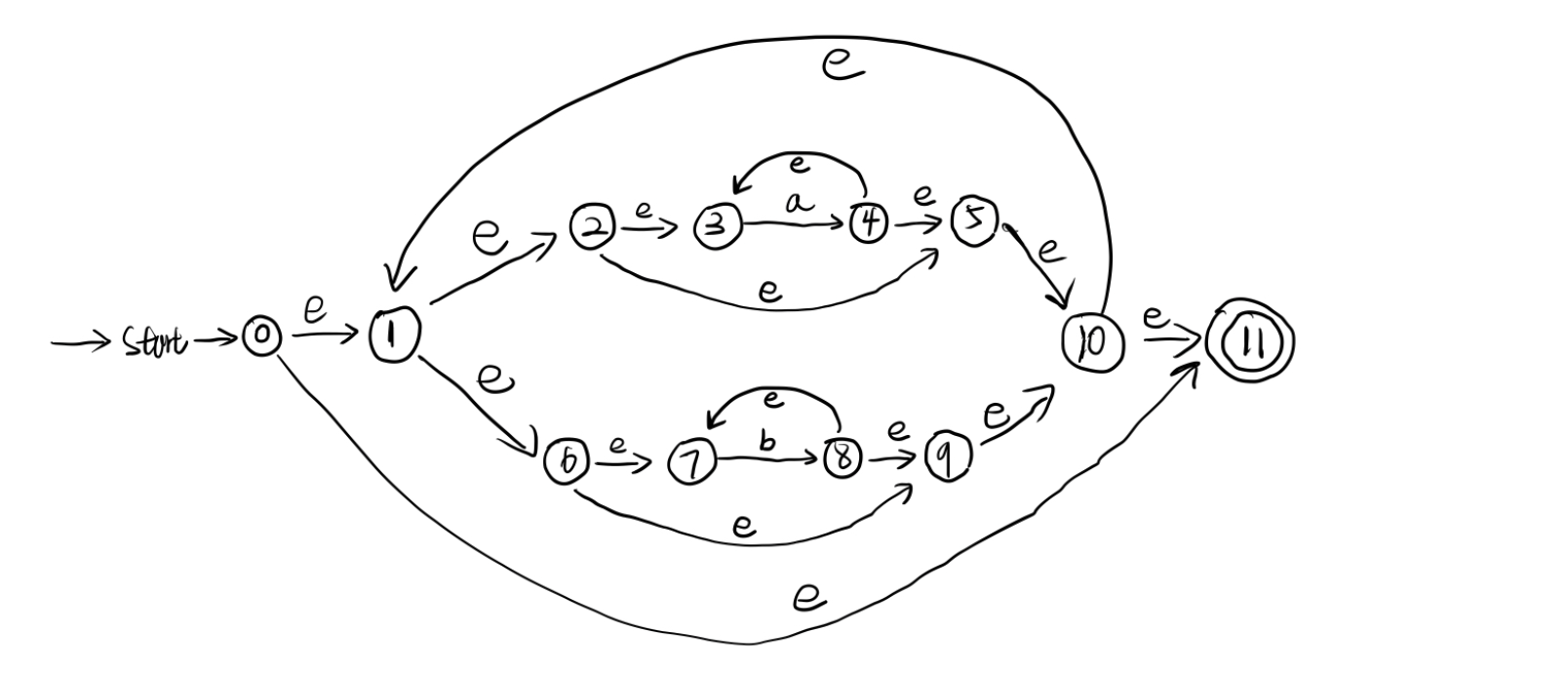
输入串ababbab 的转换序列:
0 1234510 1678910 1234510 167878910 12345610 167891011
c) ((ε|a)b*)*
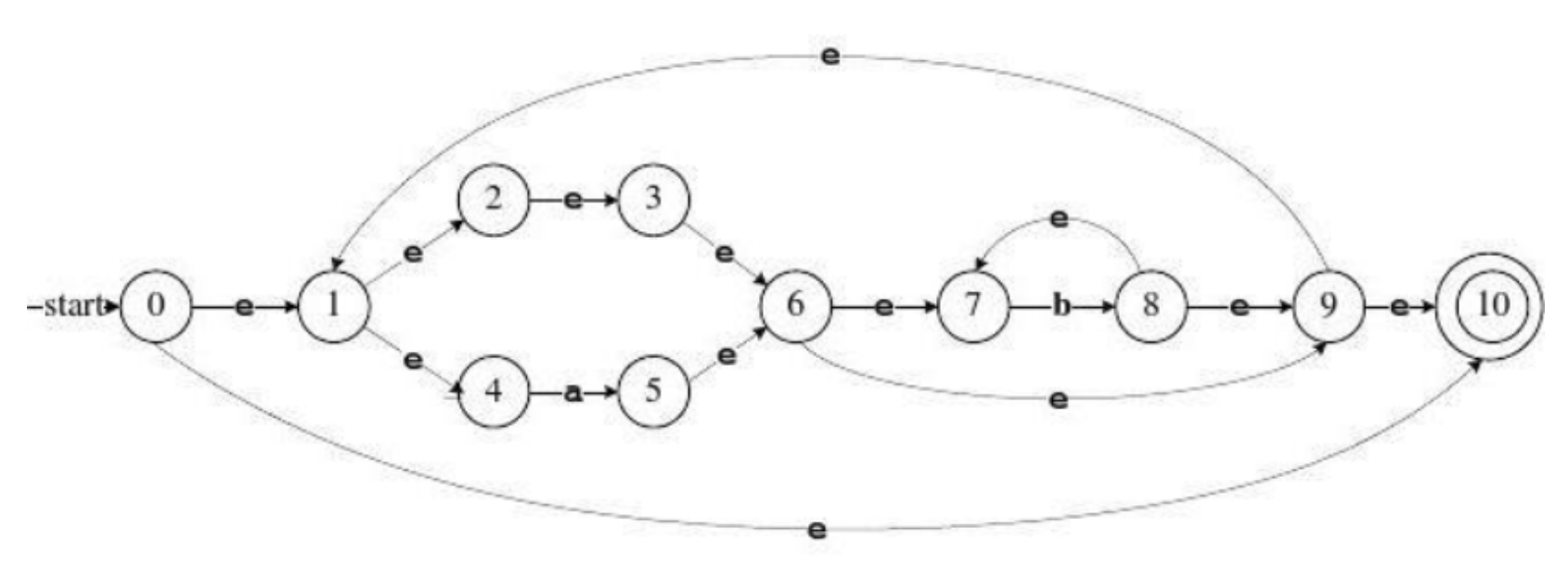
输入串ababbab 的转换序列:
0 1456789 145678 789 1456789 10
D)(a|b)abb(a|b)
NAF:
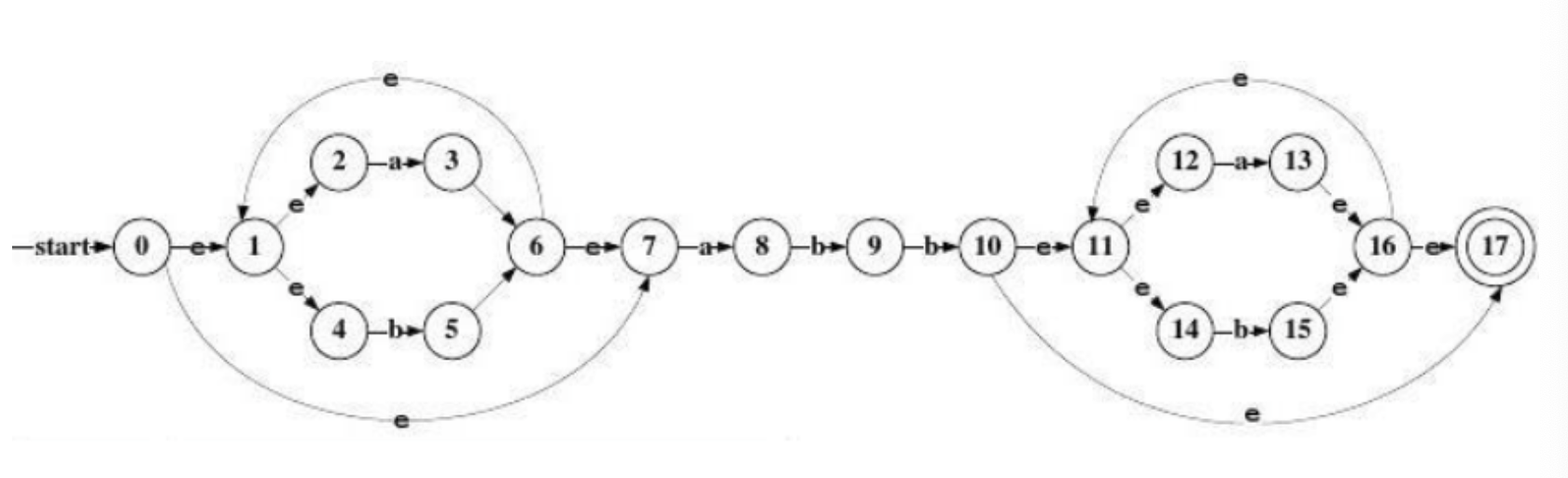
输入串ababbab 的转换序列:
0 1236 1456 789 10 11 12 13 16 11 14 15 16 17

